As mentioned in a recent blog post, our team is once again offering in-person training, and we have substantially updated our course for this occasion. Our next offering will be in Amsterdam in October 2023. To showcase our team’s new research, we are publishing a series of blog posts to offer a sneak peek at the types of analysis incorporated into the updated Malware & Memory Forensics training course.
In this blog post, we present our recent research effort to modernize Volatility’s ability to detect the usage of raw sockets by malicious applications, which led to the creation of a new Volatility 3 plugin. Before we begin the technical breakdown, we would like to take this moment to officially welcome the newest member of the Volatility core development team, Gus Moreira, who was a key contributor to this research effort. Gus began working with Volatility when he submitted to and won the 2020 Volatility plugin contest and he has since contributed many new plugins, APIs, and bug fixes to Volatility 3. We are very happy to have Gus’s help with moving Volatility 3 forward, and there will be several future blog posts detailing other research efforts in which he was deeply involved.
Raw Sockets Background
Raw sockets allow privileged applications to both read (sniff) incoming network traffic and construct packets from scratch before being sent, including creating the protocol headers. A wide variety of malicious applications have abused these features in order to steal sensitive information as it traverses the network, forge network streams, bypass network intrusion monitors, and implement custom command-and-control protocols.
The following excerpt from The Art of Memory Forensics shows how applications can use the SIO_RCVALL IOCTL to receive all packets that traverse the system:

Once the code described above is executed, the calling application can then receive all packets that traverse the system. To send raw packets, applications only need to create a socket (as shown in step 1 above). This sample project from Microsoft illustrates how to send and receive raw ICMP packets in an application.
Detecting Raw Sockets Before Windows 10
Given the danger posed by raw sockets, it is important that DFIR methodologies can be used to detect their use. Before Windows 10, it was possible to detect raw sockets using memory forensics by looking for process handles open to the “\Device\RawIp\0” device, as well as looking for sockets with a local port of “0” and protocol of “0” (HOPOPT/RAW).
The following shows how Volatility is used to find handles to the “rawip” device in a memory sample infected with the Ursnif malware:

As seen, two processes were found to have this handle open: PID 4, which is the kernel, and PID 1824.
Running the sockets plugin and searching for raw sockets also leads us to PID 1824:

In a real investigation, we could then begin to inspect this oddly named process:

Detecting Raw Sockets in Windows 10+
Due to significant changes made by Microsoft to the Windows network stack, the above methods for detecting raw sockets are no longer viable on modern versions of Windows. This led us to begin a new research project to determine how raw sockets could again be detected.
To avoid relying on indirect artifacts, such as opened handles, our main goal was to determine which data structure within the network stack was now being used to track raw sockets, since the regular socket structure seemingly did not. Analysis of the network stack requires careful and time-consuming reverse engineering, as the debug symbols for network stack driver, tcpip.sys, only provide symbol names and no types. Furthermore, Microsoft now makes significant updates to tcpip.sys between versions, so it is not always the case that previous knowledge applies directly to the latest release.
Given our team’s experience in analyzing the Windows 10+ network stack, we were pretty confident that raw sockets would now be created using their own endpoint structure, similar to how the operating system is handling TCP sockets, UDP sockets, and connections. This led us to search for related functions in IDA Pro, which brought us to RawCreateEndpoint. Analysis of this function showed that it did create a new pool allocation for raw sockets, and that the socket references its owning process. Unfortunately, we did not see where raw sockets still track their create time as other socket types still do.
The following screenshot shows the main part of this function:
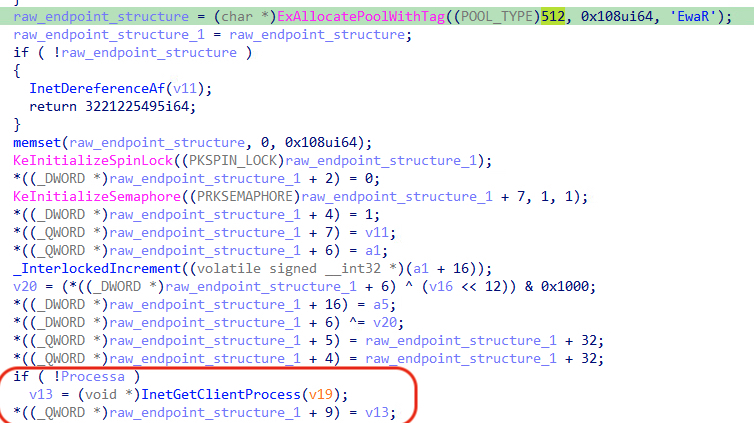
In the first line, an allocation of size “0x108” is created with a pool tag is “RawE” (after little endian conversion). The final part of the decompilation shows a reference to the owning process being acquired, which is then followed by it being placed at offset “72” within the allocated structure.
Note: We calculated the offset of the process reference as decimal “72” as the _QWORD pointer (8 bytes) times the addition operand (9) equals 72.
Developing a Raw Socket Recovery Plugin
With the information from the above decompilation, we could now develop a relatively simple Volatility 3 plugin to detect raw sockets within Windows 10+ memory samples. The first step of the plugin needed to find raw socket structures. As previously mentioned, our binary analysis showed that raw sockets are allocated within the kernel pool using a tag of “RawE”. Given the importance of pool-based data structures to memory forensics, Volatility 3 has a robust pool-scanning API that only requires plugins to fill in a few pieces of information. The following screenshot shows the few lines of code needed to enable Volatility 3 to find all instances of raw sockets:

In the above code, we are creating a pool-scanner constraint that requests scanning for pool allocations that meet the following conditions:
- An allocation tag of “RawE” (line 2)
- At least “0x50” bytes (line 4)
- In either free memory or non-paged memory (line 5)
For each pool allocation that meets the above specification, Volatility 3 will create an instance of the object whose type name is given on line 3. In this case, we have specified “_RAW_ENDPOINT”, which is a type name our team created, as the network stack does not provide type definitions.
Since we created the _RAW_ENDPOINT type based on our binary analysis, we need to inform Volatility 3 of its definition. This is accomplished through formatting a JSON file that contains the name, members, offsets, and sizes for all structures and their members. The following screenshot shows how we added support for _RAW_ENDPOINT, including marking its owning process, the “Owner” member, at offset “72” as observed in IDA Pro.

Since we only need to define one type with a single member, our JSON definition is very simple. The rest of the JSON file metadata that Volatility 3 requires can be taken from existing JSON files within the repository.
With this new type installed, the pool-scanning code will automatically find instances of our specified pool objects, and then return to us instantiated _RAW_ENDPOINT structures. Our plugin then only needs to gather the process information followed by yielding it to the display function.

The code above is responsible for verifying that each found owning process is valid (lines 4-9) and then extracting the data of interest (process name and PID). The yield statement (lines 11-17) will lead to the following code being executed by default, which prints the data formatted correctly and with descriptive headers.

Testing Our New Plugin
With the help of Volatility core developer Austin Sellers, we created two Windows 10 64-bit memory samples to test our newly developed plugin. The first sample was created while the SIO_RCVALL code (shown in the screenshot from The Art of Memory Forensics) was active. This would prove that we could detect raw sockets being used to sniff the network. The following screenshot shows our plugin against this sample, and as you can see, our plugin correctly finds our proof-of-concept program and its PID of 640.

Our second memory sample was taken when a modified version of the Microsoft raw ICMP program was running twice, each in a different configuration. The following screenshot shows our plugin correctly locating both raw sockets and correctly mapping these sockets to their owning process:

Complete Version Support
Now that we had proven our plugin worked, the final task was to ensure it worked across all Windows 10+ versions and not just the one from our test VM. The two criteria on which our plugin currently relies are the pool tag being “RawE” and the process offset being “72”. If either of those changed between versions, our plugin would fail.
To verify our cross-version support, we had two choices:
- Manually analyze RawCreateEndpoint across all the different versions
- Develop an automated approach
The manual approach had several downsides, including being time consuming and requiring significant future effort as new versions of Windows are released. Automating the process was also not trivial, as finding the RawCreateEndpointoffset within a tcpip.sys version requires downloading and parsing the PDB file followed by intricate static analysis to ensure the pool tag is constant and the offset did not change.
In the end, Gus created an automated and powerful IDA Pro script to automatically locate and analyze RawCreateEndpoint, and then report the pool tag used for the allocation along with the offset where the process reference is stored. The following shows the output from his script across our test set of tcpip.sys versions:

The output from Gus’s script showed that the tag and offset remained constant across all versions, thus making our life as plugin developers much simpler than if the offset changed often (as can occur with other data structures within the network stack).
Wrap Up
In this blog post, we documented how we were able to add detection of raw sockets on Windows 10+ systems to Volatility 3. We hope you enjoyed this peek into the memory forensics R&D process! If you missed our previous posts, be sure to read our walkthrough of detecting Mimikatz’s skeleton key attack and hidden services on Windows 10+ systems.
If you would like to try developing your own Volatility 3 capabilities, please consider submitting to the Volatility Plugin contest, where you can win prizes and gain visibility for your work!
It was great to see many of our friends and community members in Vegas during Black Hat. We really enjoy meeting members of our community, and we deeply appreciate the nearly two decades of support and friendship!
















